<파이썬 데이터분석 3주차 개발일지>
넘어오기에 너무나 오래 걸렸던 3주차, ㅋㅋ
3주차 강의는 Dart OpenAPI 를 활용하여 데이터 분석을 한다고 한다!
OpenAPI 란?
데이터를 가져다 쓸 수 있게 서버의 '창구(=문)'를 열어둔 것
dart API를 활용하면 공시 정보를 데이터 분석에 활용할 수 있고,
일일이 공시자료를 보러가지 않아도 분석을 할 수 있다고 한다.
심지어 더 쉽게 쓸 수 있도록 라이브러리를 제공하고 있는 점! (Dart FSS 라이브러리)
최대 주주 지분율 변동이 큰 회사, 이익잉여금이 크게 상승한 회사, 남녀 간의 임금 격차 등등.... 분석 가능
우선, DartOpenAPI 에 들어가서 키를 발급 받아야 한다.!
(서버가 과부하 되지 않게 할당량 만큼만 요청할 수있게 키를 받기로함)
https://opendart.fss.or.kr/uat/uia/egovLoginUsr.do
전자공시 OPENDART 시스템 | 로그인
opendart.fss.or.kr
해당 사이트에 들어가 등록하고, 로그인!
'인증키 신청/관리 - 오픈API 이용현황' 에 가면 내 Key 를 확인 할 수 있다.
colab 에서 3주차 새파일을 만들고, 라이브러리 설치
!pip install dart-fss
dart-fss 라이브러리에 가면 여러가지 공식 문서 활용법 확인 가능
https://dart-fss.readthedocs.io/en/latest/
DART-FSS — dart-fss documentation v0.3.10 documentation
© Copyright 2021, Sungwoo Jo Revision 60fa916c.
dart-fss.readthedocs.io
import dart_fss as dart_fss
import pandas as pd
api_key = '여기에 키 입력'
dart_fss.set_api_key(api_key=api_key)
corp_list = dart_fss.get_corp_list()
corp_list.corps
위 코드를 실행하면 아주 많은 종목들이 나오는 걸 확인할 수 있다.
종목 정리
dart-fss 라이브러리에서 dart api 목록을 누르면 하기와 같이 코드를 복사할 수 있다
dart_fss.api.filings.get_corp_code()( DART에 등록되어있는 공시대상회사의 고유번호,회사명,대표자명,종목코드, 최근변경일자 다운로드)
위의 코드를 all 이라는 변수에 넣고 조회해보면, 리스트안에 딕셔너리가 들어가 있는 형태로 확인 가능

위 데이터를 데이터 프레임 형태로 만들기
pd.DataFrame(all)

여기서 stock_code 가 있는 회사는 상장사, 없는 회사는 비상장사.
두 가지를 나눠서 정리하는게 보기 좋기 때문에 나누기로함.
상장사 정리는
# df['stock_code'] != 'None' 이런식으로 하면 코드가 안먹음!(난 이렇게 하려했는데!ㅋ)
df['stock_code'].notnull() # 이렇게 입력해야 none이 아니다~가 됨

비상장사 정리는
df_non_listed = df[df['stock_code'].isnull()] # 비상장사 df_non_listed하면, nono=null 인 종목들만 추려짐


엑셀 파일로 두 리스트를 저장하기
.to_excel('파일명.xlsx')

상장회사 중 특정 회사만 확인하고 싶다면,

그 중에 회사 code만 확인하고 싶다면,

해당 코드를 corp_code 라는 변수에 넣어주고,
코드 넘버를 활용해서 여러가지 dart 라이브러리를 써 볼 예정!
(dart-fss가 code를 사용해서 확인할 수 있는 정보가 많음)

dart API 에는 요런 내역들이 확인 가능하다!

그래서 확인하고 싶은 정보가 있다면, 찾기로 문자열을 검색해서, 코드를 복붙하면 됨!
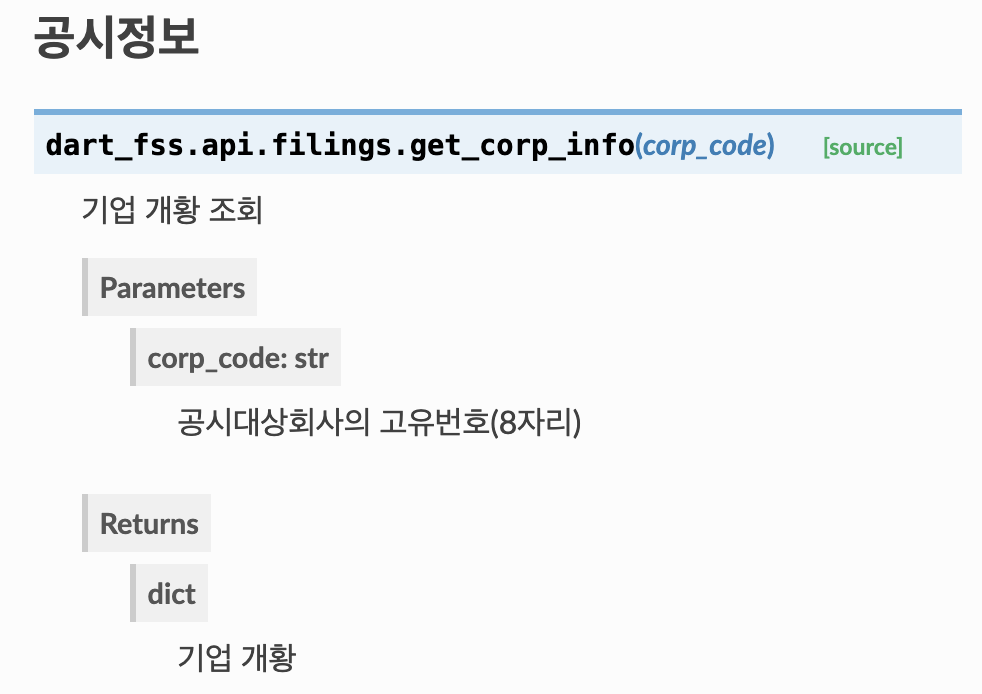
기업 개황 조회
아래와 같이 라이브러리 사이트에 확인할 수 있는 코드가 입력되어 있다.
corp_code만 넣어주면 되는 것!
corp_code = df_listed[df_listed['corp_name']=='카카오'].iloc[0,0]
dart_fss.api.filings.get_corp_info(corp_code)
여기서 잠깐!
만약 실행해서 나온 결과값이 무엇인지 모르겠다면,
dart open api 사이트에 다시 들어가서
개발가이드 - 공시정보 - 기업개황(바로가기)
를 누르면 응답키 - 명칭으로 어떤 항목인지 확인할 수가 있으니 참고!


미등기 임원 보수 총액(사업보고서 주요정보)

위와 같이 코드를 입력해주면 확인 가능함

위와 같이 필요한, 확인하고 싶은 정보들을 해당 라이브러리 사이트에서 검색하고
코드값을 입력하고 조회해보면 됨!
이후에도 여러번 연봉 많이 받은 사람, 최대주주 주식 변동 같은
여러가지 예시를 들어서 설명해 주셨기 때문에,
나중에 복습하고 싶다면 3주차 3-6, 3-7 강의를 다시 들어보는게 좋을듯!
같은 작업을 여러번 반복하니 선생님이 쓰기 전에 나도 같이 생각으로 따라가보니까 재밌음!
<반복해서 작업한 코드(비상장회사 예시 : df_non_listed)>
** 요 과정은 길어서 개발일지에 작성하지 않으려 했지만, 반복작업을 하는 것으로 보아 자주 쓰일 것 같아 제일 마지막에 복습한 비상장 회사 부분을 적었음.
물론 상장 회사는 df_listed 로 바꿔주기만 하면 방법은 똑같은데 비상장회사는 재무재표 등 이런저런 정보가 자세히 들어가 있지 않아서
내가 아는 회사, 상장회사 쪽에서 값을 찾아보는 게 좋을 것. 비상장회사는 거의 에러가 많이 나서 값이 안나옴ㅋ
기본 준비 코드
all = dart_fss.api.filings.get_corp_code() #dart-fss 에서 정체 종목을 보는 코드 복붙,
df = pd.DataFrame(all) #데이터 프레임 형태로 가져오기
df_listed = df[df['stock_code'].notnull()]
#stock_code에 none이 없으면(=코드가 있으면) 상장회사(df_listed)
df_non_listed = df[df['stock_code'].isnull()]
#stock_code에 none이라고 써져 있으면 비상장회사(df_non_listed)
① 필요한 dart-fss에서 코드 복붙 - 받아온 데이터를 데이터프레임을 만들고 리스트로 감싸주기(실행,확인)
corp_code = df_non_listed[df_non_listed['corp_name'] == '야놀자'].iloc[0,0]
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
② 확인하고 싶은 값만 뽑아오기 - 확인하고 싶은 컬럼만 뽑아오기 - 컬럼명 보기 좋게 바꾸기
df = df[df['se'] == '(연결)당기순이익(백만원)'] #확인하고 싶은 당기순이익
df = df[['corp_name','thstrm','frmtrm','lwfr']] #확인하고 싶은 특정 컬럼 추출
df.columns = ['기업명','2021','2020','2019'] #컬럼명 변경
③ 문자열인 값을 숫자로 바꿔주기
df['2021'] = df['2021'].str.replace(',','')
# 문자열을 리플레이스 메소드를 활용하여 반점을 공란으로.
df['2021'] = pd.to_numeric(df['2021'].str.replace(',',''))
# 판다스의 to_numeric으로 감싸서 숫자로 바꿔주기
df['2021'] = pd.to_numeric(df['2021'].str.replace(',',''))
df['2020'] = pd.to_numeric(df['2020'].str.replace(',',''))
df['2019'] = pd.to_numeric(df['2019'].str.replace(',',''))
④ 해당 코드를 함수로 만들어주기 - 종목명에 파라미터값을 넣어주기
def get_earning(name): # 함수추가
corp_code = df_non_listed[df_non_listed['corp_name'] == name].iloc[0,0] # name 변경
data = dart_fss.api.info.alot_matter(corp_code, '2021', '11011')
df = pd.DataFrame(data['list'])
df = df[df['se'] == '(연결)당기순이익(백만원)']
df = df[['corp_name','thstrm','frmtrm','lwfr']]
df.columns = ['기업명','2021','2020','2019']
df['2021'] = pd.to_numeric(df['2021'].str.replace(',',''))
df['2020'] = pd.to_numeric(df['2020'].str.replace(',',''))
df['2019'] = pd.to_numeric(df['2019'].str.replace(',',''))
return df # return
⑤ 비상장회사 리스트를 샘플(10개)로 받아오기 - 필요한 컬러명만 추출 - 전체를 리스트로 감싸기 - 반복할 변수명 붙여주기
df_non_listed.sample(10) # 샘플로 10개 받아오기
df_non_listed.sample(10)['corp_name'] # corp_name 추가
list(df_non_listed.sample(10)['corp_name']) # 리스트로 감싸기
names = list(df_non_listed.sample(10)['corp_name']) # 변수 지정해주기 - 완성!
⑥ 반복문을 사용해서 돌리기 - 반복문으로 추출한 값이 추가될 빈리스트 추가하기
names = list(df_non_listed.sample(10)['corp_name'])
dfs = [] #빈리스트 추가
for name in names : # for문 돌리기
⑦ for 문 안에 함수를 넣어주고 - 함수를 돌려 나온 데이터 프레임을 빈리스트에 더해주기
names = list(df_non_listed.sample(10)['corp_name'])
dfs = []
for name in names :
df = get_earning(name) # 함수 추가
dfs.append(df) # 함수로 받은 데이터를 dfs에 추가하기
⑧ pandas의 concat 기능을 활용해서, 빈리스트에 추가된 값을 하나로 합쳐 새로운 변수로 받아 결과값 확인
names = list(df_non_listed.sample(10)['corp_name'])
dfs = []
for name in names :
df = get_earning(name)
dfs.append(df)
df_result = pd.concat(dfs) # concat으로 dfs에 쌓인 리스트 합쳐주기
df_result # 완성본
⑨ 반복 과정에서 에러가 생길 수가 있으니, try, except 넣어주기
names = list(df_non_listed.sample(10)['corp_name'])
dfs = []
for name in names :
try: # try를 시도하다
df = get_earning(name)
dfs.append(df)
except: # 오류가 나면 멈추지 말고 except를 실행하라
print(f'error - {name}') # error-회사명 출력되기
df_result = pd.concat(dfs)
df_result
완성!!!
후아, 숙제로 남녀 평균 임금 차이 데이터 프레임을 만드는데
혼자 해보려니 버벅거리고 이것저것 빠트리는게 많당.ㅎ
나중에 다시 한번 강의 쭉 보면서 혼자 하는 연습을 해봐야겠당.
남자친구는 강의 본 뒤 혼자서 안보고 따라하는 연습을 하던데,
난 마냥 강의를 보고 정리만하고 ㅠ_ㅠ
실력이 제자리인것엔 이유가 있는걸까!엉엉, 나도 열심히 따라가야지!
3주차 끝!

'코딩 개발일지 > 파이썬 데이터분석(스파르타 코딩클럽)' 카테고리의 다른 글
| <스파르타 코딩클럽 파이썬 데이터분석 5주차> (0) | 2023.03.19 |
|---|---|
| <스파르타 코딩클럽 파이썬 데이터 분석 4주차> (2) | 2023.03.16 |
| <스파르타 코딩클럽 파이썬 데이터분석 2주차> (0) | 2023.03.03 |
| <스파르타 코딩클럽 파이썬 데이터분석 1주차> (0) | 2023.02.26 |